Table of Contents
Most peoples concept of a filesystem is “that thing that keeps my files organised in directories, and lets me set permissions on them”. In other words, it's just a tool for them. But there is also an implicit bargain in this, we expect a filesystem to both be quick to deliver and store the data we need, and also not corrupt any of it in any strange or unusual ways.
The problem from a filesystem developers point of view though is, to be frank, a lot harder. They are facing ever increasing disk sizes, seek times that are not keeping pace and some even wish to be able to spot (and be able to recover from) errors that corrupt your data (when your hard disk starts to fail, for instance).
Consequently, in the world of Linux, there are a number of new filesystems that are emerging to address these, and other issues.
The brief for this article was to examine the performance of emerging filesystems in Linux, so I decided to choose a mix of both real work tasks and synthetic benchmarks to test, and stress, the various filesystems I chose to work with.
If your favourite experimental filesystem isn't tested here then please accept my apologies, the ones that were chosen were those that I had already experimented with (ZFS/FUSE, NILFS, btrfs) or those that were already getting a fair amount of airplay (reiser4, ext4, ChunkFS). I also chose to throw into this mix a test of ZFS under OpenSolaris (in this case Nexenta) and would have included ZFS under FreeBSD 7 if the installer had been able to recognise the PCI ID of the Adaptec RAID card.
All the filesystems examined here use one (or more) allocation strategies when writing and arranging data on disk.
Files and directories in “block based filesystems” are constructed from one or more fixed size chunks of disk (“blocks”), this can mean that if an existing file is extended after another file has been written (or after the filesystem has been in use for some time) its blocks can be scattered across the platter (“fragmentation”) resulting in a performance penalty when reading or writing.
The original Unix filesystems were block based, as are the traditional
Linux filesystems of ext, ext2 and ext3.
Extent based filesystems take a different approach to saving file data, instead of using individual blocks they allocate a swathe of disk (the “extent”) and continue writing the file until that extent is filled. Once filled the next extent is allocated, and thus it continues. Fragmentation can still occur, however, when the filesystem is filling up.
The usual filesystem that comes to mind when extents are mentioned is
SGI's XFS, but now in Linux we have the experimental filesystem
ext4 supporting extents as well.
| Defragmenting XFS | |
|---|---|
XFS provides an online defragmentation tool called xfs_fsr that will scan an XFS filesystem looking for fragmented files and defragment them, if there is suitable free space available. For example: ino=144428307 extents before:25292 after:1 DONE ino=144428307 |
Log based filesystems are built on the premise that as the amount of RAM in a system increases the balance between reads and writes will tend to be dominated by writes as reads may be serviced by the buffer caches. Log based filesystems optimise for writing by treating the filesystem as one or more continuous buffers and always write to the head.
This means that as files are removed or truncated free space builds up in the middle of the log, and so some method of recovering that space must be provided, usually in the form of a garbage collection daemon.
The log based filesystems that will be considered here are NILFS and ZFS.
The system used for this testing was kindly loaned by Xenon Systems of Melbourne, Australia. The machine was a Krypton Duo HW2 with two dual core AMD Rev.F Opteron processors, 8GB of RAM (expandable to 64GB) and 8 73GB Seagate Cheetah 15K.5 Serial Attached SCSI (SAS) drives driven through an Adaptec 31605 16 Port SAS RAID Controller (AAC RAID family).
The drives were not made into a hardware RAID set but instead presented individually to the host O/S. This is easier said than done with the 31605 RAID card as you must go in and create a JBOD array for each drive rather than just not configuring any arrays at all. Write caching for all drives was disabled to reduce any confounding effect.
The reason for not using a single RAID array was to allow the comparison of ZFS/FUSE handling of striping with running ZFS/FUSE over a software RAID stripe.

The system was installed with Ubuntu 7.04 server, I chose to use the 32-bit version rather than the 64-bit version as it is more likely that this is the primary development platform and the code is then ported to 64-bit architectures. Certainly this seems to be true for NILFS.
The 2.6.22.1 kernel (the latest stable release at the time of testing)
was used and the base configuration was imported from the Ubuntu 7.04
2.6.20-16-server. No major changes were made from that, asides from
including the EXT4 developmental filesystem (see below) as the
Ubuntu kernel config already sets the CONFIG_EXPERIMENTAL option.
There was a single RAID volume created across 7 of the SAS drives using mdadm thus:
# mdadm --create /dev/md0 --level=0 --raid-devices=7 /dev/sdb1 /dev/sdc1 /dev/sdd1 /dev/sde1 /dev/sdf1 /dev/sdg1 /dev/sdh1
That yielded the following array, shown in /proc/mdstat as:
Personalities : [raid0]
md0 : active raid0 sdh1[6] sdg1[5] sdf1[4] sde1[3] sdd1[2] sdc1[1] sdb1[0]
500929856 blocks 64k chunksThis 500GB software RAID array was used as the basis for testing all of the filesystems listed below under Linux.
The Linux kernel is fantastically helpful to the kernel, if you are doing a lot of file I/O and have RAM to spare then the kernel will allocate a portion of that to buffer and file cache to accelerate I/O through to the disk. In a test machine with 8GB of RAM that isn't doing much else other than benchmarking then there is plenty of that free for such tasks. Now that is great if you're doing real work, but for benchmarks it is an absolute nightmare as you end up testing how effectively the kernel can cache rather than how well the filesystem performs.
Synthetic benchmarks like Bonnie++ go to great lengths to work around this; for example Bonnie++ defaults to using files of a size that total twice the amount of RAM in the system.
Of course real world tests can't do that so I have attempted to split up the standard “extract tarball, configure, make” sequences up and interleave them together, throwing the synthetic benchmarks in as well to keep the kernel on its toes and (hopefully) keep the cache full of information that is irrelevant to the next test stage.
Of course it would be virtually impossible to reproduce the same steps
each time without any sequencing errors or typos, especially when some
of the tests can take an hour or longer, and attempting to do so is a
recipe for madness and a lot of late nights. So instead the whole
sequence of testing was scripted so that a new filesystem could be
brought up and a full test run started and left running under the
ever wonderful screen program.
For those who haven't used |
The actual tests run, in the order they execute, are listed below.
Con Kolivas's kernbench
times kernel builds with differing -j values, firstly a half load
test of -j3, optimal load of -j16 and the full-bore -j which
will run as many as possible.
Here we just look at the overall time of a “fast” (-f) run which
avoids caching the kernel files in RAM - as otherwise we wouldn't be
looking at the differences that the filesystem brings!
It appears that |
The GCC compilation system has a very useful feature for us, the make
bootstrap option performs a three stage build of GCC. The stage1
build uses the system compiler, stage2 uses the stage1 compiler and
stage3 uses stage2.
It then compares the stage 2 and stage 3 builds and, if all is well, they should be identical. If not then something went wrong, and if it hasn't failed on the standard kernel filesystems we can be pretty confident that it is related to the filesystem being tested.
We also time this make -j16 bootstrap for comparison.
Because ELF object files include a 16 byte header which can change
from build to build the GCC build system skips the first 16 bytes of
the object files produced. This can be seen in the following output from
|
checking how to compare bootstrapped objects... cmp --ignore-initial=16 $$f1 $$f2
To give the kernel a thorough work out and clear its caches of any
remnant of the GCC build (in case removing the Linux source tree
didn't fix it) we now run Russell Cokers
Bonnie++, disabling all tests
except the file creation, stat and removal tests. We use the -n 100
option to make it run these tests using 102,400 files.
This is timed for comparison and the results tabulated for each filesystem.
When a Bonnie++ test stage completes in less than 500ms it produces
output of the form |
As a comparison I ran my test script against a set of standard filesystems in the Linux kernel that most users will be familiar with.
As well as being of general interest it also gives a good range of values to use as a baseline when comparing the emerging filesystems.
The ext2 filesystem was introduced into the Linux kernel in January 1993 and was the principle filesystem until the introduction of ext3 in 2001. It is a fixed block size filesystem and has no journalling capabilities.
| Test | Time (secs) |
|---|---|
| Total | 3232.9 |
| Extract kernel sources | 2.7 |
| Extract GCC sources | 4.0 |
| Recursive random file | 22.7 |
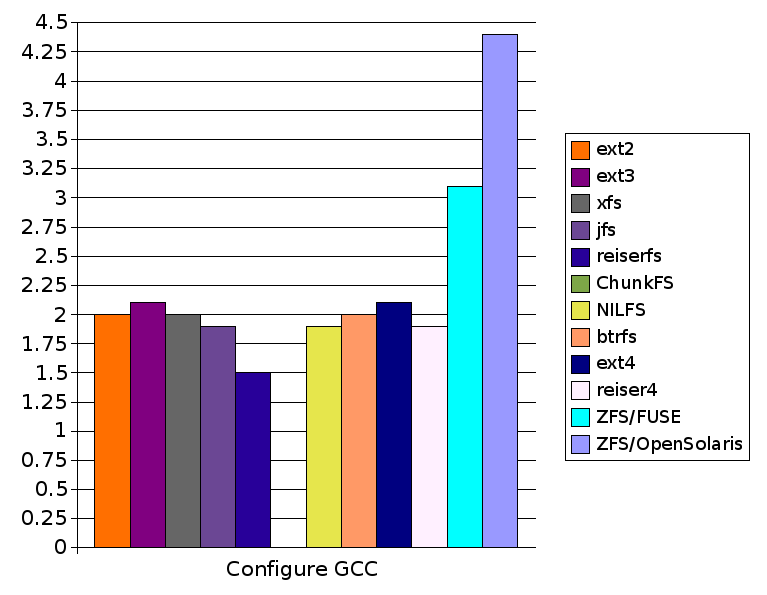
| Configure GCC | 2.0 |
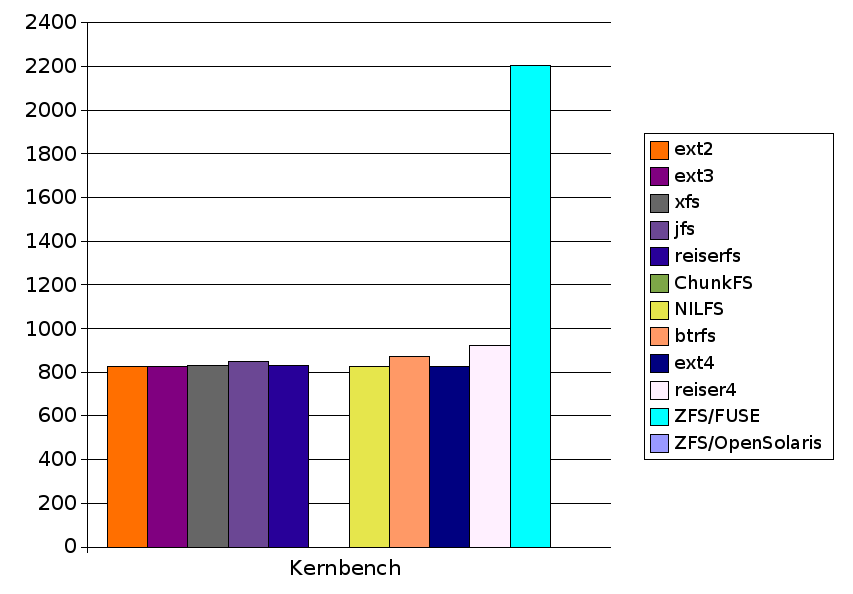
| Kernbench | 824.5 |
GCC make -j16 bootstrap
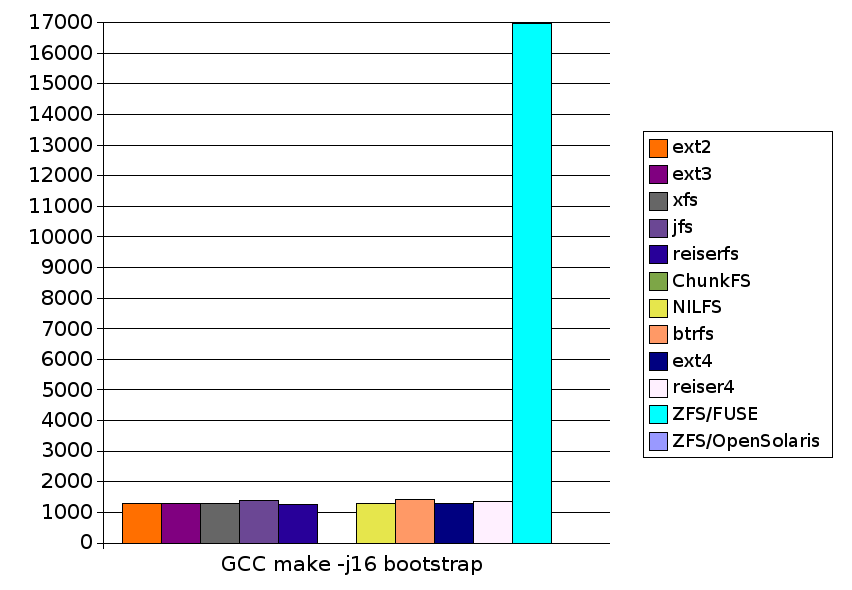
| 1288.3 |
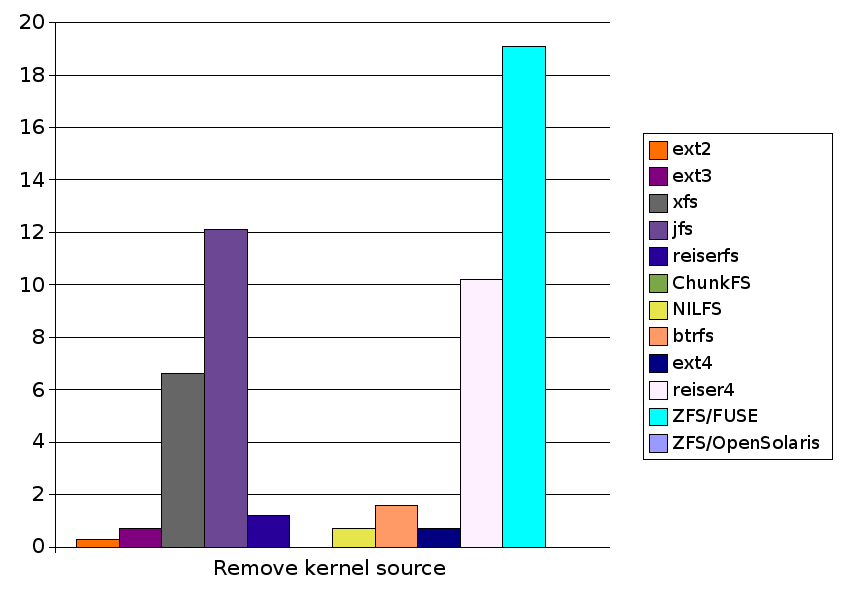
| Remove kernel source | 0.3 |
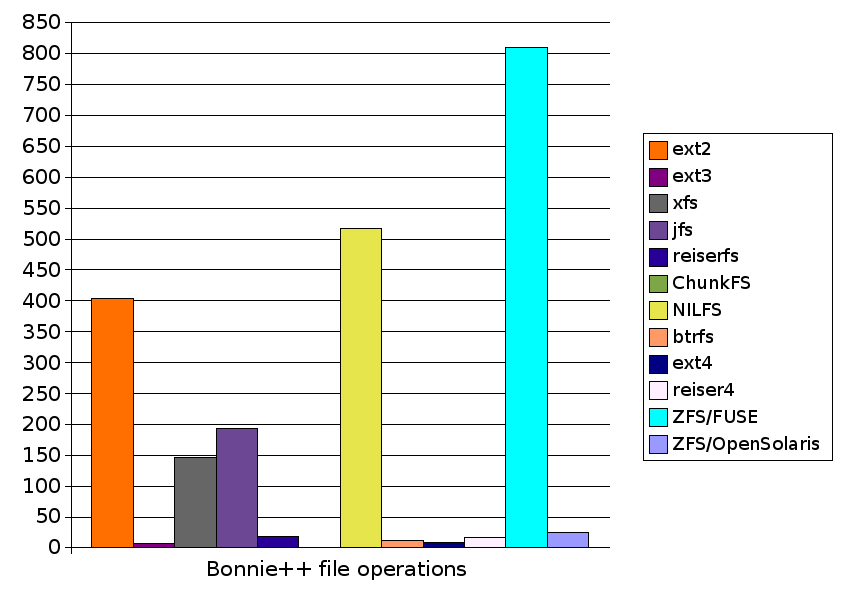
| Bonnie++ file operations | 403.3 |
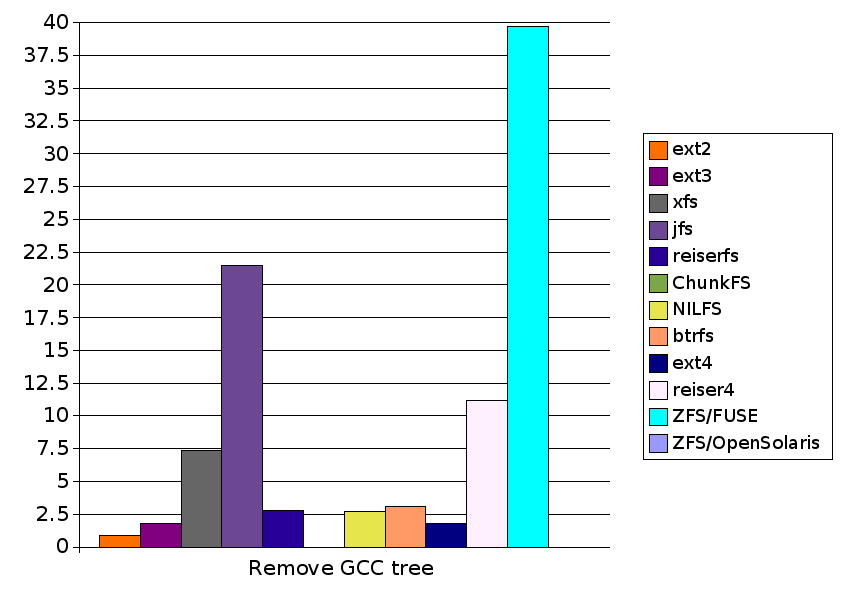
| Remove GCC tree | 0.9 |
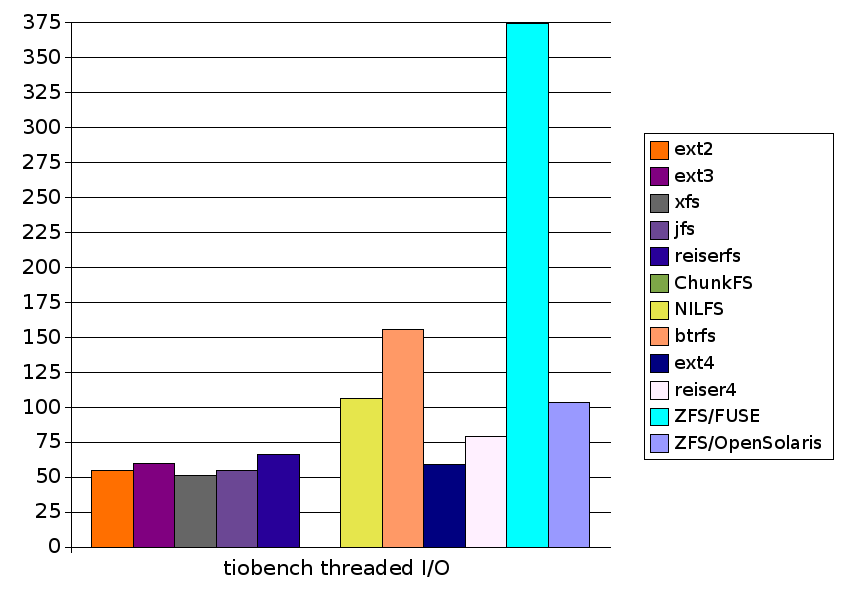
| tiobench threaded I/O | 54.9 |
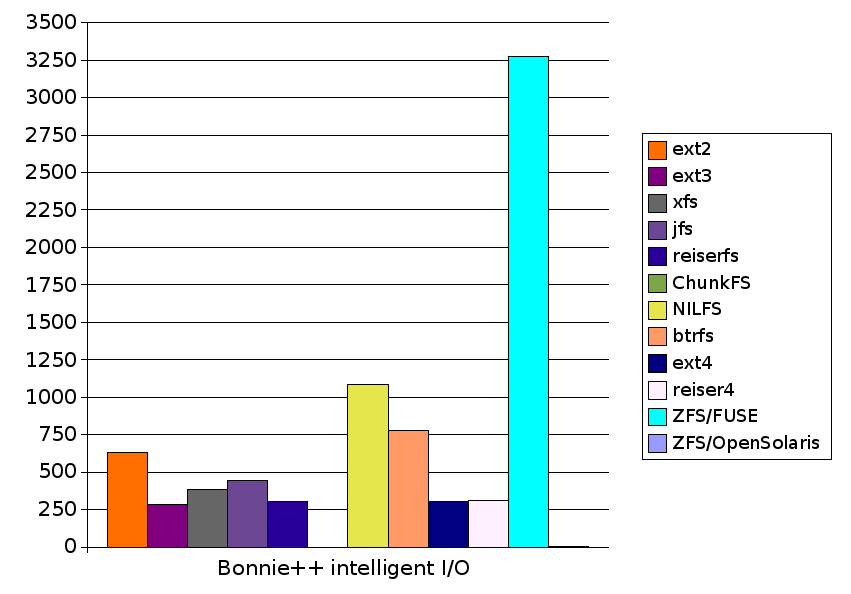
| Bonnie++ intelligent I/O | 629.1 |
The third extended filesystem (ext3) was introduced into the
mainline Linux kernel in 2001 to provide a filesystem that was
backwards and forwards compatible with ext2 but which provided
journalling of both metadata and (optionally) data.
In its default mode of data=ordered it also provides a higher
guarantee of filesystem consistency by ensuring that file data is
flushed to disk before the corresponding metadata.
| Test | Time (secs) |
|---|---|
| Total | 2509.9 |
| Extract kernel sources | 4.0 |
| Extract GCC sources | 5.4 |
| Recursive random file | 22.5 |
| Configure GCC | 2.1 |
| Kernbench | 828.1 |
GCC make -j16 bootstrap
| 1290.4 |
| Remove kernel source | 0.7 |
| Bonnie++ file operations | 7.9 |
| Remove GCC tree | 1.8 |
| tiobench threaded I/O | 59.9 |
| Bonnie++ intelligent I/O | 286.6 |
SGI's XFS began life in the mid 90's in Irix, their Unix variant, but in 1999 they announced they were going to contribute it to Linux. It finally arrived in Linux in the 2.5.36 kernel on the 17th September 2002 and then in the 2.4.24 kernel on the 5th February 2004.
XFS is a 64-bit extents based filesystem capable of scaling up to 9 Exabytes, though on 32-bit Linux systems there are kernel constraints that limit it to 16TB for both filesystems and individual files.
| Test | Time (secs) |
|---|---|
| Total | 2782.4 |
| Extract kernel sources | 8.1 |
| Extract GCC sources | 13.6 |
| Recursive random file | 22.7 |
| Configure GCC | 2.0 |
| Kernbench | 832.2 |
GCC make -j16 bootstrap
| 1307.3 |
| Remove kernel source | 6.6 |
| Bonnie++ file operations | 145.6 |
| Remove GCC tree | 7.4 |
| tiobench threaded I/O | 51.1 |
| Bonnie++ intelligent I/O | 385.4 |
JFS is a filesystem developed by IBM, it first appeared in the 2.5.6 development kernel on March 8th, 2002 and then backported to 2.4.20 which was released on the 28th November 2002.
JFS is an extents based filesystem and can extend to 4 Petabytes with 4KB block sizes.
| Test | Time (secs) |
|---|---|
| Total | 3064.5 |
| Extract kernel sources | 10.5 |
| Extract GCC sources | 18.7 |
| Recursive random file | 22.1 |
| Configure GCC | 1.9 |
| Kernbench | 847.6 |
GCC make -j16 bootstrap
| 1387.9 |
| Remove kernel source | 12.1 |
| Bonnie++ file operations | 193.4 |
| Remove GCC tree | 21.5 |
| tiobench threaded I/O | 54.9 |
| Bonnie++ intelligent I/O | 443.8 |
Reiserfs (actually Reiserfs version 3) was the first journalling filesystem to be included into the mainline Linux kernel, arriving in the 2.4.1 release on January 29th, 2001.
It uses a novell tree structure for files as well as directories and claims space-efficiency through its “tail-packing” of small files, though this feature can have performance impacts too and can be disabled if necessary.
| Test | Time (secs) |
|---|---|
| Total | 2531.8 |
| Extract kernel sources | 3.1 |
| Extract GCC sources | 5.0 |
| Recursive random file | 25.0 |
| Configure GCC | 1.5 |
| Kernbench | 831.4 |
GCC make -j16 bootstrap
| 1273.9 |
| Remove kernel source | 1.2 |
| Bonnie++ file operations | 18.1 |
| Remove GCC tree | 2.8 |
| tiobench threaded I/O | 66.2 |
| Bonnie++ intelligent I/O | 303.3 |
- Authors: Amit Gud, Val Henson, et. al
- Website(s): http://linuxfs.pbwiki.com/chunkfs
ChunkFS is based on ideas from Arjan van de Ven and Val Henson to counter the “fsck problem” caused by seek times not keeping up with disk sizes and bandwidth. It was discussed at the 2006 Linux Filesystems Workshop and again at the 2007 Workshop.
In their Usenix paper they describe the filesystem, saying:
There are two early implementations of ChunkFS at present, one is a straight kernel filesystem and the second is implemented as a user space filesystem using FUSE. Both use the ext2 filesystem code underneath the covers.
Both the FUSE and kernel versions as well as their associated toolsets are available via git from http://git.kernel.org/.
To retrieve the FUSE version of ChunkFS I installed the cogito package which provides a higher level interface to GIT and then cloned the repository thus:
# apt-get install cogito # cg-clone git://git.kernel.org/pub/scm/linux/kernel/git/gud/chunkfs.git
As it is a FUSE filesystem it requires some dependencies to be pulled in which are documented in the INSTALL files:
# apt-get install e2fslibs e2fslibs-dev fuse-utils libfuse-dev libfuse2
There is one undocumented dependency too:
# apt-get install pkg-config
To build it the usual routine is followed:
# ./configure --prefix=/usr/local/chunkfs-fuse-trunk # make # make install
It appears the FUSE version lags somewhat behind the kernel version, though the FUSE version is easier to debug as it is fairly easy to run it under GDB.
I had expected the straight kernel filesystem version of ChunkFS to simply be a kernel module, so upon trying to clone it I was surprised to find out that it was its own self contained kernel tree! Thus began a rather painful experience.
I began by importing my existing kernel config file for the 2.6.22.1 build I was already using and enabled it as a module. I also took notice of the text on the ChunkFS PBwiki page which says:
Unfortunately I was then greeted with this error during the build:
ERROR: "shrink_dcache_for_umount" [fs/chunkfs/chunkfs.ko] undefined! ERROR: "super_blocks" [fs/chunkfs/chunkfs.ko] undefined! ERROR: "sb_lock" [fs/chunkfs/chunkfs.ko] undefined!
Telling it to build directly into the kernel worked, however, so it appears that (for the moment) ChunkFS will not build as a module.
However, when trying to boot this kernel it would panic on boot. Turning to Amit Gud, one of the developers, he was able to supply me with an extremely cut down kernel .config that he was using. I was able to take that and by carefully only enabling what was essential (PCI device support, SCSI support, Adaptec AACRAID driver, networking, etc) I was able to get the system to boot.
However, certainly not yet recommended for beginners!
To be able to create a ChunkFS filesystem for either version of the filesystem you need the ChunkFS version of mkfs which again is available through git.
# cg-clone git://git.kernel.org/pub/scm/linux/kernel/git/gud/chunkfs-tools.git # cd chunkfs-tools # ./configure --prefix=/usr/local/chunkfs-fuse-trunk # make # make install
As I had 7 drives in the RAID-0 stripe I decided to set that as the number of chunks to create within the ChunkFS filesystem, like so:
# /usr/local/chunkfs-fuse-trunk/sbin/mkfs -C 7 /dev/md0
However, it was rapidly apparent that this was incredibly slow, and
that it appeared to be rather a lot of I/O for each chunk. A quick
investigation into the code showed that a missing break; in the
argument checking code was causing the -C option to drop through
into the -c option and setting the variable to enable bad block
checking. Fortunately pretty easy to fix!
This patch has been submitted upstream, but it has not yet been committed out to the kernel.org git repository, so you may want to check for yourself if you wish to experiment. |
Mounting the FUSE filesystem is the same as running any other user
process, here we pass through the -o option to specify the chunks we
created previously with the custom mkfs command. You will notice
that the same device is referenced 7 times, that's once for each chunk
specified with the -C option. Finally we specify the mount point.
# /usr/local/chunkfs-fuse-trunk/sbin/chunkfs -o chunks=/dev/md0:/dev/md0:/dev/md0:/dev/md0:/dev/md0:/dev/md0:/dev/md0 /mnt
Here we look at the FUSE and the kernel version separately.
| Test | Time (secs) |
|---|---|
| Total | Invalid due to above failures |
| Extract kernel sources | 47.5 |
| Extract GCC sources | 116.2 |
| Recursive random file | 26.2 |
| Configure GCC |
Failed, ../configure: Permission denied
|
| Kernbench | Failed, returned 0 seconds for each run |
GCC make -j16 bootstrap
| Failed as configure didn't complete. |
| Remove kernel source | chunkfs-fuse process crashed during this. |
| Bonnie++ file operations | N/A |
| Remove GCC tree | N/A |
| tiobench threaded I/O | N/A |
| Bonnie++ intelligent I/O | N/A |
The FUSE variant seemed rather fragile, a reproducible crash prior to the results above was tracked down to a buffer overrun when the name of a file to be unlinked was being passed through. This code only appears in the FUSE variant, not the kernel version as that doesn't require this glue layer.
- Authors: The NILFS Development Team, NTT Laboratories
- Website(s): http://www.nilfs.org/en/
NILFS is a log based filesystem developed in Japan by NTT Laboratories designed to provide continuous “checkpoints” (as well as on demand) which can be converted into snapshots (a persistent checkpoint) at a later date, before the checkpoint expires and is cleaned up by the garbage collector. These snapshots are separately mountable as read-only filesystems and can be converted back into checkpoints (for garbage collection) at a later date.
It has what appears to be a rather nicely thought out set of user
commands to create (mkcp), list (lscp), change (chcp) and remove
(rmcp) checkpoints.
Installation of NILFS is reasonably straightforward. I grabbed the
2.0.0-testing-3 versions of both the nilfs kernel module and the
nilfs-utils package and extracted them into their own directories.
The kernel module builds as an out-of-tree module so it just a matter of:
# cd nilfs-2.0.0-testing-3 # make # make install
to get the necessary kernel module installed into
/lib/modules/2.6.22.1+ext4/kernel/fs/nilfs2/.
The utilities package uses the standard autoconf tools, I built them with:
# cd nilfs-utils-2.0.0-testing-3 # ./configure --prefix=/usr/local/nilfs-utils-2.0.0-testing-3 # make -j4 # make install
Then I found out that it it didn't completely honour the —prefix
option I had passed through, as it did:
/usr/bin/install -c .libs/nilfs_cleanerd /sbin/nilfs_cleanerd /usr/bin/install -c mkfs.nilfs2 /sbin/mkfs.nilfs2 /usr/bin/install -c mount.nilfs2 /sbin/mount.nilfs2 /usr/bin/install -c umount.nilfs2 /sbin/umount.nilfs2
This will be to allow for the way that mount, mkfs, etc work when
passed the -t <fstype> option.
Creating a NILFS filesystem is very easy:
# mkfs.nilfs /dev/md0
Mounting is again very simple:
# mount -t nilfs2 /dev/md0 /mnt
| Test | Time (secs) |
|---|---|
| Total | 3870.5 |
| Extract kernel sources | 5.5 |
| Extract GCC sources | 8.2 |
| Recursive random file | 22.4 |
| Configure GCC | 1.9 |
| Kernbench | 827.0 |
GCC make -j16 bootstrap
| 1293.6 |
| Remove kernel source | 0.7 |
| Bonnie++ file operations | 517.6 |
| Remove GCC tree | 2.7 |
| tiobench threaded I/O | 106.5 |
| Bonnie++ intelligent I/O | 1084.4 |
- Authors: Chris Mason, Oracle
- Website(s): http://oss.oracle.com/projects/btrfs/
On the 12th June 2007 Chris Mason announced a new filesystem that both checksums and does copy on write logging of all file data and metadata information called “btrfs”. It also includes features such as space-efficient packing of small files, which should not be surprising given Chris's history with the reiserfs project.
Unlike most filesystems the root of the btrfs filesystem is not for
users, it is instead a place to keep various “sub-volumes”. These
sub-volumes are described as named b-tree which can be be optionally
allocated a fix number of blocks which it cannot exceed (a quota).
These sub-volumes can be snapshotted and either the original or the
snapshot can be written too, with the filesystem using copy-on-write
to constrain changes to that b-tree.
As the announcement and website says this filesystem is in very early alpha, the on-disk format isn't fixed yet and it doesn't handle a filesystem running out of space gracefully (or at all, really). |
To build btrfs I grabbed btrfs-0.5.tar.bz2 and
btrfs-progs-0.5.tar.bz2 from the
downloads page and
extracted them.
Btrfs builds as an out of tree kernel module so all that was needed was:
# cd btrfs-0.5 # make
There is no make install option for this version of btrfs, so to
load the kernel module it was necessary to first load the 32-bit CRC
module and then the btrfs module, thus:
# modprobe crc32c # insmod btrfs.ko
The btrfs-progs package required no configuration, just supplying a
Makefile which simply required an edit to change the prefix variable
to /usr/local/btrfs-0.5 and then doing the usual:
# make # make install
This time everything was installed directly under the prefix directory.
Creating a btrfs filesystem follows the standard pattern of:
# mkfs.btrfs /dev/md0
Mounting that filesystem is again through the standard method of:
# mount -t btrfs /dev/md0 /mnt
Unlike the other filesystems you will find that you cannot write into
the top level directory, but you will find a default directory
already there. This is because btrfs reserves that top level directory
for sub-volumes and snapshots.
You can use the btrfsctl -s <subvol> <btrfs-mountpoint> command to
create a new sub-volume, or just work in the default subvolume, which
is what I chose to do.
| Test | Time (secs) |
|---|---|
| Total | 3268.5 |
| Extract kernel sources | 6.3 |
| Extract GCC sources | 8.0 |
| Recursive random file | 23.0 |
| Configure GCC | 2.0 |
| Kernbench | 870.9 |
GCC make -j16 bootstrap
| 1411.1 |
| Remove kernel source | 1.6 |
| Bonnie++ file operations | 12.5 |
| Remove GCC tree | 3.1 |
| tiobench threaded I/O | 155.6 |
| Bonnie++ intelligent I/O | 774.5 |
| Test | Result |
|---|---|
| Sequential create/sec | 33454 |
| Sequential stats/sec | +++++ |
| Sequential delete/sec | 37457 |
| Random create/sec | 34521 |
| Random stat/sec | +++++ |
| Random delete/sec | 31331 |
| Block writes KB/sec | 101102 |
| Block rewrites KB/sec | 46907 |
| Block read KB/sec | 121205 |
| Random seeks/sec | 257.8 |
After the testing I happened to do a dmesg and noticed the following
checksum errors reported back, though they didn't appear to affect any
of the testing that was being done.
[208284.710000] btrfs: md0 checksum verify failed on 273600 [208422.630000] btrfs: md0 checksum verify failed on 295841
- Authors: Too many to mention! Based upon ext3, ext2, ext..
- Website(s): http://ext4.wiki.kernel.org/index.php/Main_Page
The workhorse filesystem of the Linux kernel is ext3, it entered the
mainline kernel in 2001 when 2.4.15 was released and can currently support
filesystems up to 8TB and files up to 2TB (if your hardware supports 8KB
pages then it can reach to 32TB and 16TB respectively). Those limits are
now becoming a problem and patches to
increase those limits have been circulating for a while, but have never
been merged precisely because ext3 is so important. In June 2006 Linus
wrote on the
Linux filesystem development list:
Quite frankly, at this point, there's no way in hell I believe we can do major surgery on ext3. It's the main filesystem for a lot of users, and it's just not worth the instability worries unless it's something very obviously transparent. | ||
| -- | ||
So near the end of June 2006 Ted T'so posted his “Proposal and plan for ext2/3 future development work” to the Linux kernel mailing list giving his four point plan for ext4 development, phase 1 (where we are at present) being:
1) The creation of a new filesystem codebase in the 2.6 kernel tree in /usr/src/linux/fs/ext4 that will initially register itself as the "ext3dev" filesystem. This will be explicitly marked as an CONFIG_EXPERIMENTAL filesystem, and will in affect be a "development fork" of ext3. A similar split of the fs/jbd will be made in order to support 64-bit jbd, which will be used by fs/ext4 and future versions of ocfs2. | ||
| -- | ||
The only difference with the current state of play is that the filesystem
has ended up being ext4dev rather than ext3dev.
As ext4 has arrived in the mainline kernel as an experimental
filesystem, enabling it was just a matter of selecting “Ext4dev/ext4
extended fs support development” (CONFIG_EXT4DEV_FS) as a module
under File systems in the kernel configuration, before building the
kernel.
There are no ext4 specific packages required for ext4, development of the current e2fsprogs package to support ext4 is happening in git and you will only require these if you need to build an ext4 filesystem that requires 64-bit addressing.
Be warned though that ext4 support in e2fsck is fairly new and may not handle all the new features yet! |
Creating an ext4 filesystem is identical to creating an ext3 filesystem:
# mkfs.ext3 /dev/md0
It is only when you mount the filesystem that it becomes ext4:
# mount -t ext4dev -o extents /dev/md0 /mnt
In early July a patch was submitted to make the |
Once you have mounted an ext3 filesystem using ext4 with extents enabled (as it appears they will be by default in 2.6.23) ext3 will not be able to mount it again! |
| Test | Time (secs) |
|---|---|
| Total | 2527.0 |
| Extract kernel sources | 4.0 |
| Extract GCC sources | 5.6 |
| Recursive random file | 22.8 |
| Configure GCC | 2.1 |
| Kernbench | 828.3 |
GCC make -j16 bootstrap
| 1293.3 |
| Remove kernel source | 0.7 |
| Bonnie++ file operations | 8.5 |
| Remove GCC tree | 1.8 |
| tiobench threaded I/O | 58.9 |
| Bonnie++ intelligent I/O | 300.6 |
- Authors: Namesys
- Website(s): http://www.namesys.com/v4/v4.html
On the 24th July 2003 Hans Reiser of Namesys posted to LKML asking for people to look at his benchmarks of the new Reiser4 filesystem compared to Reiserfs and ext3 and asked for inclusion into the 2.5 development kernel ready for the release of 2.6.
It is now over 4 years later and Reiser4 still is not included in the mainline kernel, though it has at least made it into Andrew Mortons mm series in August 2004 when 2.6.8.1-mm2 was released. The reasons are many and rather than go into them here I would direct interested people to this 2005 LWN article on the matter.
As Reiser4 isn't in the mainline kernels yet I picked what was at the time the latest in Andrew Mortons “mm” series, 2.6.22-rc6-mm1. All that was necessary to import the .config file I was already using and tell it to include Reiser4 support when prompted in the filesystems section, as below:
Reiser4 (EXPERIMENTAL) (REISER4_FS) [N/m/y/?] (NEW) m
The kernel built with no issues.
Ubuntu happens to package version 1.0.5 of reiser4progs in its main repository, even though their packaged kernels do not yet support it. Installing them is as easy as
# apt-get install reiser4progs
You can then create a reiser4 filesystem simply by doing:
# mkfs.reiser4 /dev/md0
Mounting it is also trivial, again we just need to specify the filesystem name.
# mount -t reiser4 /dev/md0 /mnt
The first attempt with reiser4 ended rather unhappily with a crash part way through the testing which killed the filesystem.
| Test | Time (secs) |
|---|---|
| Total | |
| Extract kernel sources | 4.3 |
| Extract GCC sources | 6.1 |
| Recursive random file | 23.1 |
| Configure GCC | 2.0 |
| Kernbench | Filesystem crashed (see below). |
GCC make -j16 bootstrap
| |
| Remove kernel source | |
| Bonnie++ file operations | |
| Remove GCC tree | |
| tiobench threaded I/O | |
| Bonnie++ intelligent I/O |
Example 1. Reiser4 crash
[ 81.600000] Loading Reiser4. See www.namesys.com for a description of Reiser4. [ 81.620000] reiser4: md0: found disk format 4.0.0. [ 162.730000] reiser4[pdflush(265)]: disable_write_barrier (fs/reiser4/wander.c:234)[zam-1055]: [ 162.730000] NOTICE: md0 does not support write barriers, using synchronous write instead. [ 862.270000] reiser4[fixdep(4426)]: parse_node40 (fs/reiser4/plugin/node/node40.c:672)[nikita-494]: [ 862.270000] WARNING: Wrong level found in node: 1 != 113 [ 862.270000] reiser4[fixdep(4426)]: extent2tail (fs/reiser4/plugin/file/tail_conversion.c:662)[]: [ 862.270000] WARNING: reiser4_write_tail failed [ 862.270000] reiser4[fixdep(4426)]: release_unix_file (fs/reiser4/plugin/file/file.c:2378)[nikita-3233]: [ 862.270000] WARNING: Failed (-5) to convert in release_unix_file (82406) [ 862.270000] reiser4[fixdep(5010)]: parse_node40 (fs/reiser4/plugin/node/node40.c:672)[nikita-494]: [ 862.270000] WARNING: Wrong level found in node: 1 != 113 [ 862.270000] reiser4[fixdep(5010)]: extent2tail (fs/reiser4/plugin/file/tail_conversion.c:662)[]: [ 862.270000] WARNING: reiser4_write_tail failed [ 862.270000] reiser4[fixdep(5010)]: release_unix_file (fs/reiser4/plugin/file/file.c:2378)[nikita-3233]: [ 862.270000] WARNING: Failed (-5) to convert in release_unix_file (82407) [ 862.270000] reiser4[fixdep(4292)]: parse_node40 (fs/reiser4/plugin/node/node40.c:672)[nikita-494]: [ 862.270000] WARNING: Wrong level found in node: 1 != 113
And so on. Not a pretty sight.
The second attempt a few days later, after remaking the filesystem, was more successful.
| Test | Time (secs) |
|---|---|
| Total | 2732.8 |
| Extract kernel sources | 4.5 |
| Extract GCC sources | 6.1 |
| Recursive random file | 23.0 |
| Configure GCC | 1.9 |
| Kernbench | 922.2 |
GCC make -j16 bootstrap
| 1344.9 |
| Remove kernel source | 10.2 |
| Bonnie++ file operations | 16.6 |
| Remove GCC tree | 11.2 |
| tiobench threaded I/O | 79.0 |
| Bonnie++ intelligent I/O | 313.0 |
- Authors: Ricardo Correia (FUSE port), Sun Microsystems (original ZFS)
- Website(s): http://www.wizy.org/wiki/ZFS_on_FUSE
ZFS, originally the Zettabyte File System, now just the initials, was created by Sun Microsystems and is a log based, copy-on-write filesystem with reference counting, snapshots and checksums of data on disk.
The basic concept of using ZFS is to put physical disks or arrays into a storage pool using some RAID-like strategy (striping, mirroring, RAIDZ, or some combination of these) and then carve off filesystems from that pool for use.
The filesystems carved off can have different attributes set on them such as compression, storing multiple copies of data for resilience, etc, and can inherit these attributes from their parents.
There has been much interest from outside the Solaris community about ZFS, and there are already working ports in the current development versions of Apple's MacOSX and FreeBSD. A direct Linux port was made much harder by the decision of Sun to create a new license, the CDDL, for their open sourced version of Solaris called OpenSolaris which is widely believed to be incompatible with the GPL used in the Linux kernel.
In 2006 Google's Summer of Code program included an application to provide the ZFS filesystem for FUSE/Linux, taking advantage of the fact that by running the filesystem in user space with FUSE the licensing problems would not be an issue.
Whilst the Summer of Code 2006 has finished Ricardo has carried on working on the port and it has now reached beta stage.
| RAIDZ - Danger, Will Robinson! | |
|---|---|
On July 25th 2007 Riccardo posted to the ZFS/FUSE mailing list saying: Unfortunately he's not yet responded to a query about whether this is limited to ZFS/FUSE (probable) or ZFS in general (which should have been picked up by now you would have thought). |
ZFS/FUSE uses Mercurial for its source code control, and builds using
scons rather than the usual make program. To install both those it
was simply a matter of doing:
# apt-get install mercurial scons
Grabbing the trunk of ZFS/FUSE and building and install ZFS/FUSE is then done with:
# hg clone http://www.wizy.org/mercurial/zfs-fuse/trunk # cd trunk # cd src # scons -j 4 # scons install install_dir=/usr/local/zfs-trunk
The ZFS commands now live directly under /usr/local/zfs-trunk.
I first created a new “pool” of storage (called zfs, but it could
have been called anything) from which to later create ZFS filesystems
and checked its status. The pool name is also used as the top level
mountpoint (which will be /zfs in this case), but I could have changed
that by using the -m <mountpoint> option.
# zpool create zfs /dev/md0
# zpool status
pool: zfs
state: ONLINE
scrub: none requested
config:
NAME STATE READ WRITE CKSUM
zfs ONLINE 0 0 0
md0 ONLINE 0 0 0
errors: No known data errorsThe “scrub” mentioned above is a periodic check of the checksums of all the data that can be requested to try and spot problems with data that hasn't been accessed for a while.
Now I can create a ZFS filesystem called testing from the zfs pool
to use for testing and then look at what is available, thus:
# zfs create zfs/testing # zfs list NAME USED AVAIL REFER MOUNTPOINT zfs 130K 469G 19K /zfs zfs/testing 18K 469G 18K /zfs/testing
By default each zfs filesystem in that pool shares the same free space, though you can constrain that through quotas should you wish.
Quotas are just one of a myriad of options that can be set on a ZFS
filesytem, others that may be of interest are compression (to enable
or disable compression on a filesystem) and copies (to store
multiple copies of data for extra redundancy). Here is the full list
as returned by the zfs command. Note that several of them are, as of
the moment, unimplemented including the snapdir visible option,
which isn't noted as such below.
The following properties are supported:
PROPERTY EDIT INHERIT VALUES
type NO NO filesystem | volume | snapshot
creation NO NO <date>
used NO NO <size>
available NO NO <size>
referenced NO NO <size>
compressratio NO NO <1.00x or higher if compressed>
mounted NO NO yes | no | -
origin NO NO <snapshot>
quota YES NO <size> | none
reservation YES NO <size> | none
volsize YES NO <size>
volblocksize NO NO 512 to 128k, power of 2
recordsize YES YES 512 to 128k, power of 2
mountpoint YES YES <path> | legacy | none
sharenfs YES YES on | off | share(1M) options # not yet implemented
checksum YES YES on | off | fletcher2 | fletcher4 | sha256
compression YES YES on | off | lzjb | gzip | gzip-[1-9]
atime YES YES on | off
devices YES YES on | off
exec YES YES on | off
setuid YES YES on | off
readonly YES YES on | off
zoned YES YES on | off
snapdir YES YES hidden | visible
aclmode YES YES discard | groupmask | passthrough
aclinherit YES YES discard | noallow | secure | passthrough
canmount YES NO on | off
shareiscsi YES YES on | off | type=<type> # not yet implemented
xattr YES YES on | off
copies YES YES 1 | 2 | 3
Sizes are specified in bytes with standard units such as K, M, G, etc.
User-defined properties can be specified by using a name containing a colon (:).At the time of testing ZFS/FUSE was going through work to convert it
to using O_DIRECT for file I/O to prevent the kernel duplicating
ZFS's own caching. This gave me the opportunity to compare ZFS/FUSE
both before and after.
| Test | Time (secs) |
|---|---|
| Total | 20813.0 |
| Extract kernel sources | 47.2 |
| Extract GCC sources | 69.0 |
| Recursive random file | 61.3 |
| Configure GCC | 2.6 |
| Kernbench | 1963.8 |
GCC make -j16 bootstrap
| 16573.7 |
| Remove kernel source | 14.7 |
| Bonnie++ file operations | 277.0 |
| Remove GCC tree | 37.1 |
| tiobench threaded I/O | 183.9 |
| Bonnie++ intelligent I/O | 1582.6 |
Yes, the tests really did run for almost 6 hours. Ricardo is very clear that he has not yet started on performance optimisations in ZFS/FUSE, he is currently concentrating purely on getting it functional rather than fast.
| Test | Time (secs) |
|---|---|
| Total | 23989.0 |
| Extract kernel sources | 76.7 |
| Extract GCC sources | 111.0 |
| Recursive random file | 113.3 |
| Configure GCC | 3.1 |
| Kernbench | 2202.2 |
GCC make -j16 bootstrap
| 16966.0 |
| Remove kernel source | 19.1 |
| Bonnie++ file operations | 810.0 |
| Remove GCC tree | 39.7 |
| tiobench threaded I/O | 374.7 |
| Bonnie++ intelligent I/O | 3273.0 |
| Test | Result |
|---|---|
| Sequential create/sec | 3446 |
| Sequential stats/sec | 4155 |
| Sequential delete/sec | 727 |
| Random create/sec | 1195 |
| Random stat/sec | 3250 |
| Random delete/sec | 205 |
| Block writes KB/sec | 27017 |
| Block rewrites KB/sec | 11529 |
| Block read KB/sec | 31963 |
| Random seeks/sec | 273.1 |
Comparing before and after we can see that the implementation of O_DIRECT has negatively impacted performance, when I asked Ricardo about this on the ZFS/FUSE mailing list he responded saying:
Unfortunately those fixes haven't yet appeared in the Mercurial repository, at the time of writing the last commit is changeset 244, the final part of the O_DIRECT work, which is over 4 weeks old.
- Authors: Sun Microsystems
- Website(s): http://www.opensolaris.org/os/community/zfs/
Given that the ZFS/FUSE filesystem is so new to Linux it would be very interesting to see how alternative implementations under OpenSolaris and FreeBSD would fare on the same hardware.
Unfortunately, this turned out to be much harder to try than was initially expected as Linux's excellent hardware support had raised expectations for these other OS's and early hopes for painless installs were dashed. The latest snapshot of FreeBSD 7 available at the time of testing, 200706, could not recognise the RAID card. Neither could the latest releases of the OpenSolaris derived distributions Nexenta or Belenix.
In the end success was only possible with the latest snapshot of
Nexenta available, ncp_beta1-test3-b68 which had an AAC driver new
enough to recognise the Adaptec 31605. It was installed using ZFS as
its root on a single drive.
Nexenta is dubbed “GnuSolaris” as it is loosely based on the Ubuntu
userland, providing a mixed OpenSolaris and GNU environment with an
OpenSolaris kernel. The usual apt-get commands are provided but it
became apparent that there were some issues with the provided
repositories as it was (and still is) impossible to upgrade the
system:
# apt-get update [...] # apt-get dist-upgrade Reading package lists... Done Building dependency tree... Done You might want to run `apt-get -f install' to correct these. The following packages have unmet dependencies: dpkg-dev: Depends: sunwtoo but it is not installed gcc-4.0: Depends: sunwtoo but it is not installed E: Unmet dependencies. Try using -f. # apt-get -f install Reading package lists... Done Building dependency tree... Done Correcting dependencies... Done The following extra packages will be installed: sunwtoo The following NEW packages will be installed: sunwtoo 0 upgraded, 1 newly installed, 0 to remove and 0 not upgraded. Need to get 469kB of archives. After unpacking 49.2kB of additional disk space will be used. Do you want to continue [Y/n]? Err http://apt.gnusolaris.org elatte-unstable/main sunwtoo 5.11.68-1 404 Not Found Failed to fetch http://apt.gnusolaris.org/dists/unstable/main/binary-solaris-i386/utils/sunwtoo_5.11.68-1_solaris-i386.deb 404 Not Found E: Unable to fetch some archives, maybe run apt-get update or try with --fix-missing?
However, these issues did not prevent testing using the standard install.
ZFS is a standard part of OpenSolaris, and Nexenta was able to install
into a ZFS root partition using a pool called syspool containing
just a single drive.
# zpool status
pool: syspool
state: ONLINE
scrub: none requested
config:
NAME STATE READ WRITE CKSUM
syspool ONLINE 0 0 0
c1t0d0s0 ONLINE 0 0 0
errors: No known data errorsThe 7 spare SAS drives were then added in to make another pool called,
as before, zfs.
# zpool create zfs c1t1d0 c1t2d0 c1t3d0 c1t4d0 c1t5d0 c1t6d0 c1t7d0
# zpool status
pool: syspool
state: ONLINE
scrub: scrub completed with 0 errors on Sun Aug 5 03:54:43 2007
config:
NAME STATE READ WRITE CKSUM
syspool ONLINE 0 0 0
c1t0d0s0 ONLINE 0 0 0
errors: No known data errors
pool: zfs
state: ONLINE
scrub: none requested
config:
NAME STATE READ WRITE CKSUM
zfs ONLINE 0 0 0
c1t1d0 ONLINE 0 0 0
c1t2d0 ONLINE 0 0 0
c1t3d0 ONLINE 0 0 0
c1t4d0 ONLINE 0 0 0
c1t5d0 ONLINE 0 0 0
c1t6d0 ONLINE 0 0 0
c1t7d0 ONLINE 0 0 0
errors: No known data errorsYou can also see that in between the first and second zpool status
commands I had done a scrub of the system pool by issuing the
following command to see if it could detect any issues.
# zpool scrub syspool
Some failures in this section were expected, if nothing else due to the fact that Nexenta isn't completely a Linux user space.
| Test | Time (secs) |
|---|---|
| Total | Invalid due to above failures |
| Extract kernel sources | 22.7 |
| Extract GCC sources | 23.4 |
| Recursive random file | 62.2 |
| Configure GCC | 4.4 |
| Kernbench | Failed |
GCC make -j16 bootstrap
| Failed (not filesystem related) |
| Remove kernel source | 2.6 |
| Bonnie++ file operations | 24.3 |
| Remove GCC tree | 4.0 |
| tiobench threaded I/O | 103.6 |
| Bonnie++ intelligent I/O | 276.6 |
It was not surprising that kernbench failed as it parses /proc/meminfo and /proc/cpuinfo under Linux to learn how much RAM and how many CPUs are available, and then in an evaluation working on a blank variable:
/usr/local/bin/kernbench: line 116: / 2 : syntax error: operand expected (error token is "/ 2 ")
The GCC error appears to be an issue with the build process, it
appears to decide it needs to rebuild java/parse-scan.c from the
original yacc file but bison is not yet packaged for Nexenta so
the builds fails at that point.
xgcc: java/parse-scan.c: No such file or directory xgcc: no input files
Of course with those failures the overall runtime cannot be compared to other tests.
| Test | Result |
|---|---|
| Sequential create/sec | 25833 |
| Sequential stats/sec | 56906 |
| Sequential delete/sec | 22659 |
| Random create/sec | 17033 |
| Random stat/sec | 52337 |
| Random delete/sec | 17519 |
| Block writes KB/sec | 176336 |
| Block rewrites KB/sec | 142455 |
| Block read KB/sec | 777394 |
| Random seeks/sec | 857.1 |
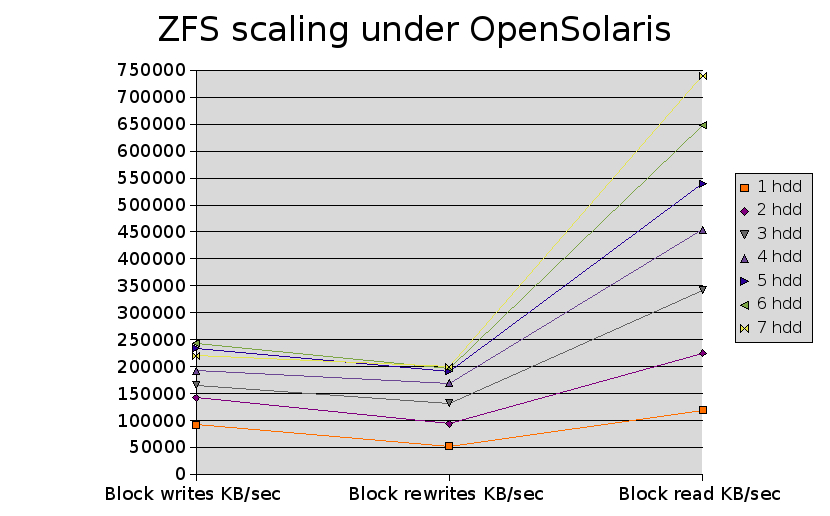
Testing ZFS under OpenSolaris allowed testing of Bonnie++ with various numbers of disks being striped over in the pool to see how well it scales.
| Test | 1 hdd | 2 hdd | 3 hdd | 4 hdd | 5 hdd | 6 hdd | 7 hdd |
|---|---|---|---|---|---|---|---|
| Block writes KB/sec | 92114 | 142045 | 165665 | 192073 | 233764 | 243971 | 219900 |
| Block rewrites KB/sec | 52554 | 94132 | 131955 | 169213 | 191697 | 197541 | 199777 |
| Block read KB/sec | 119435 | 225301 | 342184 | 454014 | 539671 | 648393 | 739724 |
| Test | ext2 | ext3 | xfs | jfs | reiserfs |
|---|---|---|---|---|---|
| Total | 3232.9 | 2509.9 | 2782.4 | 3064.5 | 2531.8 |
| Extract kernel sources | 2.7 | 4.0 | 8.1 | 10.5 | 3.1 |
| Extract GCC sources | 4.0 | 5.4 | 13.6 | 18.7 | 5.0 |
| Recursive random file | 22.7 | 22.5 | 22.7 | 22.1 | 25.0 |
| Configure GCC | 2.0 | 2.1 | 2.0 | 1.9 | 1.5 |
| Kernbench | 824.5 | 828.1 | 832.2 | 847.6 | 831.4 |
GCC make -j16 bootstrap
| 1288.3 | 1290.4 | 1307.3 | 1387.9 | 1273.9 |
| Remove kernel source | 0.3 | 0.7 | 6.6 | 12.1 | 1.2 |
| Bonnie++ file operations | 403.3 | 7.9 | 145.6 | 193.4 | 18.1 |
| Remove GCC tree | 0.9 | 1.8 | 7.4 | 21.5 | 2.8 |
| tiobench threaded I/O | 54.9 | 59.9 | 51.1 | 54.9 | 66.2 |
| Bonnie++ intelligent I/O | 629.1 | 286.6 | 385.4 | 443.8 | 303.3 |
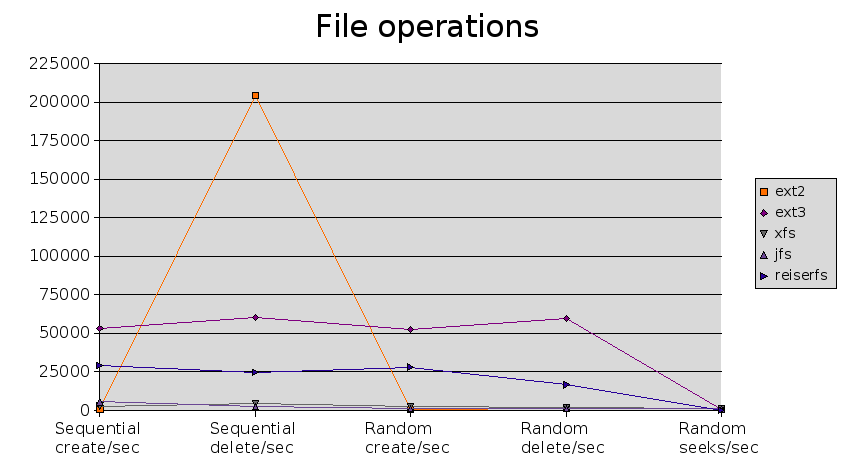
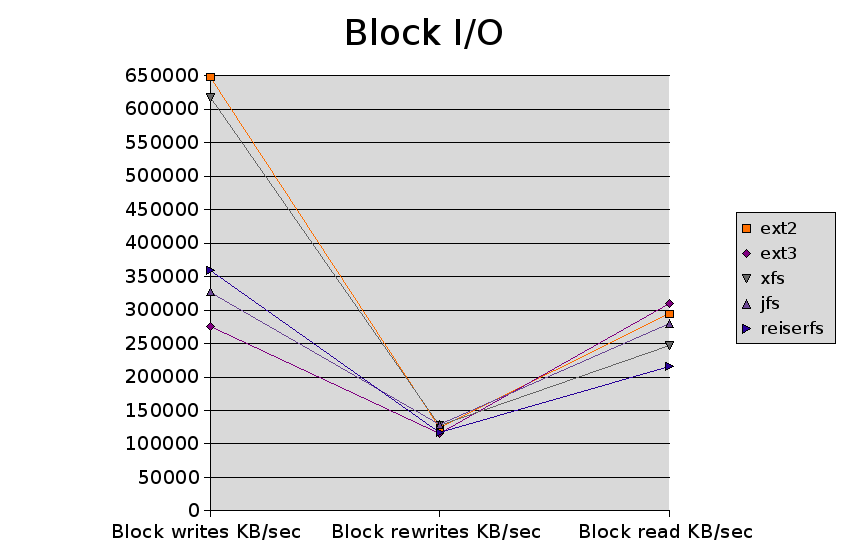
| Test | ext2 | ext3 | xfs | jfs | reiserfs |
|---|---|---|---|---|---|
| Sequential create/sec | 651 | 53412 | 2894 | 5562 | 29107 |
| Sequential stats/sec | +++++ | +++++ | +++++ | +++++ | +++++ |
| Sequential delete/sec | 204531 | 60123 | 4602 | 2761 | 24549 |
| Random create/sec | 639 | 52744 | 2643 | 1556 | 28179 |
| Random stat/sec | +++++ | +++++ | +++++ | +++++ | +++++ |
| Random delete/sec | 1204 | 59555 | 2109 | 1432 | 16623 |
| Block writes KB/sec | 648084 | 275239 | 617869 | 327055 | 359405 |
| Block rewrites KB/sec | 123908 | 115008 | 128171 | 128943 | 116784 |
| Block read KB/sec | 294471 | 309794 | 246910 | 279747 | 215436 |
| Random seeks/sec | 1007 | 991.9 | 1404 | 1060 | 989.1 |
| Test | ChunkFS | NILFS | btrfs | ext4 | reiser4 | ZFS/FUSE | ZFS/OpenSolaris |
|---|---|---|---|---|---|---|---|
| Total | N/A | 3870.5 | 3268.5 | 2527.0 | 2732.8 | 23989.0 | N/A |
| Extract kernel sources | 47.5 | 5.5 | 6.3 | 4.0 | 4.5 | 76.7 | 22.7 |
| Extract GCC sources | 116.2 | 8.2 | 8.0 | 5.6 | 6.1 | 111.0 | 23.4 |
| Recursive random file | 26.2 | 22.4 | 23.0 | 22.8 | 23.0 | 113.3 | 62.2 |
| Configure GCC | Fail | 1.9 | 2.0 | 2.1 | 1.9 | 3.1 | 4.4 |
| Kernbench | Fail | 827.0 | 870.9 | 828.3 | 922.2 | 2202.2 | N/A |
GCC make -j16 bootstrap
| Crash | 1293.6 | 1411.1 | 1293.3 | 1344.9 | 16966.0 | N/A |
| Remove kernel source | N/A | 0.7 | 1.6 | 0.7 | 10.2 | 19.1 | N/A |
| Bonnie++ file operations | N/A | 517.6 | 12.5 | 8.5 | 16.6 | 810.0 | 24.3 |
| Remove GCC tree | N/A | 2.7 | 3.1 | 1.8 | 11.2 | 39.7 | N/A |
| tiobench threaded I/O | N/A | 106.5 | 155.6 | 58.9 | 79.0 | 374.7 | 103.6 |
| Bonnie++ intelligent I/O | N/A | 1084.4 | 774.5 | 300.6 | 313.0 | 3273.0 | 276.6 |
| Test | ChunkFS | NILFS | btrfs | ext4 | reiser4 | ZFS/FUSE | ZFS/OpenSolaris |
|---|---|---|---|---|---|---|---|
| Sequential create/sec | N/A | 495 | 33454 | 48103 | 54286 | 3446 | 25833 |
| Sequential stats/sec | N/A | +++++ | +++++ | +++++ | +++++ | 4155 | 56906 |
| Sequential delete/sec | N/A | 118726 | 37457 | 52397 | 21880 | 727 | 22659 |
| Random create/sec | N/A | 495 | 34521 | 52234 | 23215 | 1195 | 17033 |
| Random stat/sec | N/A | +++++ | +++++ | +++++ | +++++ | 3250 | 52337 |
| Random delete/sec | N/A | 993 | 31331 | 57264 | 21318 | 205 | 17519 |
| Block writes KB/sec | N/A | 102669 | 101102 | 291673 | 446526 | 27017 | 176336 |
| Block rewrites KB/sec | N/A | 60190 | 46907 | 103971 | 122194 | 11529 | 142455 |
| Block read KB/sec | N/A | 177609 | 121205 | 281596 | 173377 | 31963 | 777394 |
| Random seeks/sec | N/A | 519.6 | 257.8 | 1245 | 1249 | 273.1 | 857.1 |
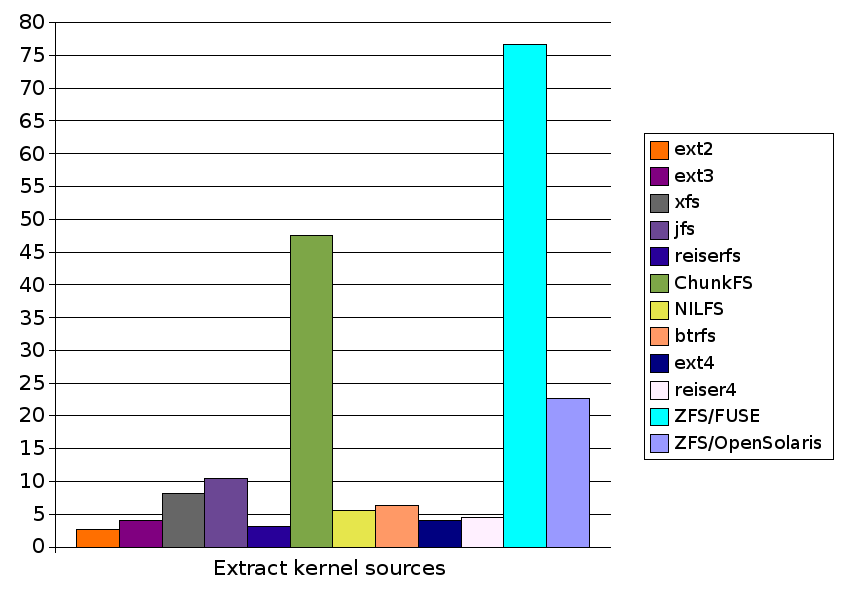
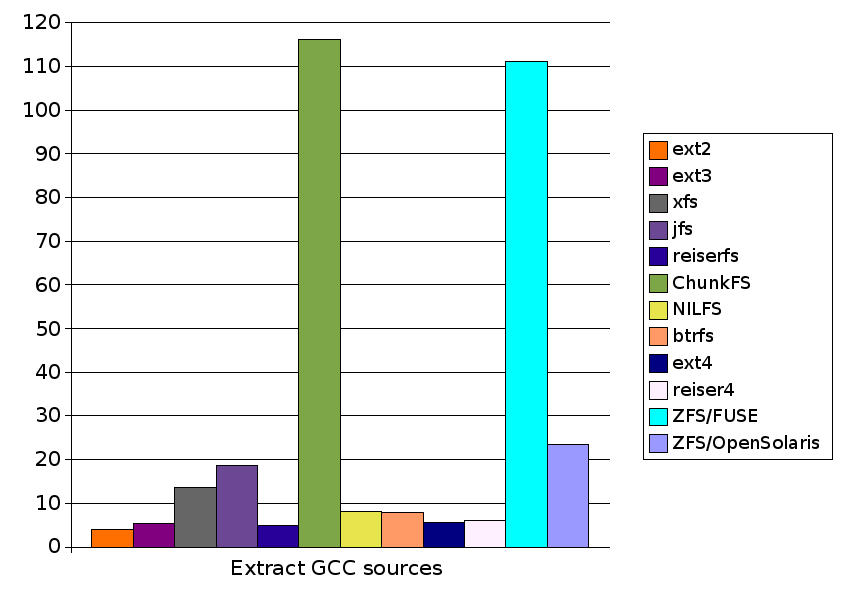
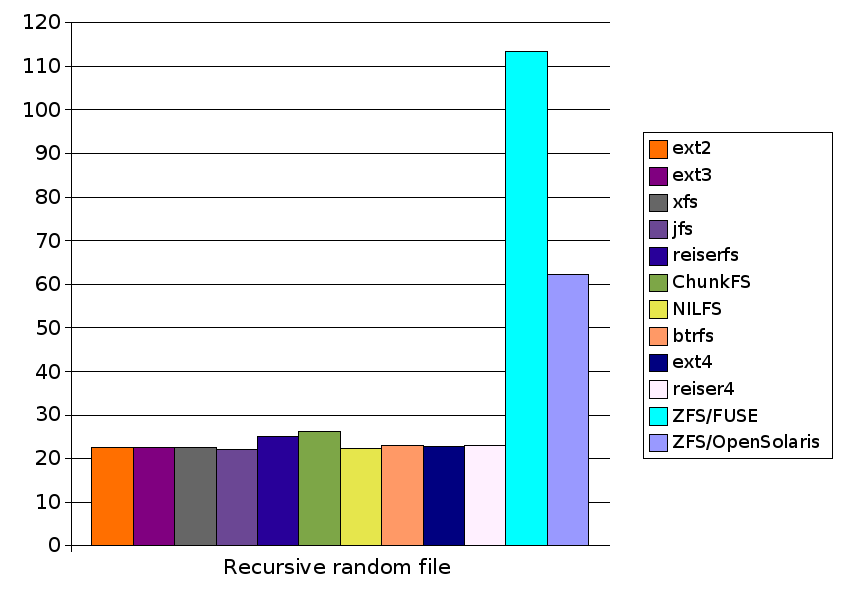
| Test | ext2 | ext3 | xfs | jfs | reiserfs | ChunkFS | NILFS | btrfs | ext4 | reiser4 | ZFS/FUSE | ZFS/OpenSolaris |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Total | 3232.9 | 2509.9 | 2782.4 | 3064.5 | 2531.8 | N/A | 3870.5 | 3268.5 | 2527.0 | 2732.8 | 23989.0 | N/A |
| Extract kernel sources | 2.7 | 4.0 | 8.1 | 10.5 | 3.1 | 47.5 | 5.5 | 6.3 | 4.0 | 4.5 | 76.7 | 22.7 |
| Extract GCC sources | 4.0 | 5.4 | 13.6 | 18.7 | 5.0 | 116.2 | 8.2 | 8.0 | 5.6 | 6.1 | 111.0 | 23.4 |
| Recursive random file | 22.7 | 22.5 | 22.7 | 22.1 | 25.0 | 26.2 | 22.4 | 23.0 | 22.8 | 23.0 | 113.3 | 62.2 |
| Configure GCC | 2.0 | 2.1 | 2.0 | 1.9 | 1.5 | Fail | 1.9 | 2.0 | 2.1 | 1.9 | 3.1 | 4.4 |
| Kernbench | 824.5 | 828.1 | 832.2 | 847.6 | 831.4 | Fail | 827.0 | 870.9 | 828.3 | 922.2 | 2202.2 | N/A |
GCC make -j16 bootstrap
| 1288.3 | 1290.4 | 1307.3 | 1387.9 | 1273.9 | Crash | 1293.6 | 1411.1 | 1293.3 | 1344.9 | 16966.0 | N/A |
| Remove kernel source | 0.3 | 0.7 | 6.6 | 12.1 | 1.2 | N/A | 0.7 | 1.6 | 0.7 | 10.2 | 19.1 | N/A |
| Bonnie++ file operations | 403.3 | 7.9 | 145.6 | 193.4 | 18.1 | N/A | 517.6 | 12.5 | 8.5 | 16.6 | 810.0 | 24.3 |
| Remove GCC tree | 0.9 | 1.8 | 7.4 | 21.5 | 2.8 | N/A | 2.7 | 3.1 | 1.8 | 11.2 | 39.7 | N/A |
| tiobench threaded I/O | 54.9 | 59.9 | 51.1 | 54.9 | 66.2 | N/A | 106.5 | 155.6 | 58.9 | 79.0 | 374.7 | 103.6 |
| Bonnie++ intelligent I/O | 629.1 | 286.6 | 385.4 | 443.8 | 303.3 | N/A | 1084.4 | 774.5 | 300.6 | 313.0 | 3273.0 | 276.6 |
The scale on the left hand side is in seconds, where less is better (faster). Filesystems with no bar shown failed that test.
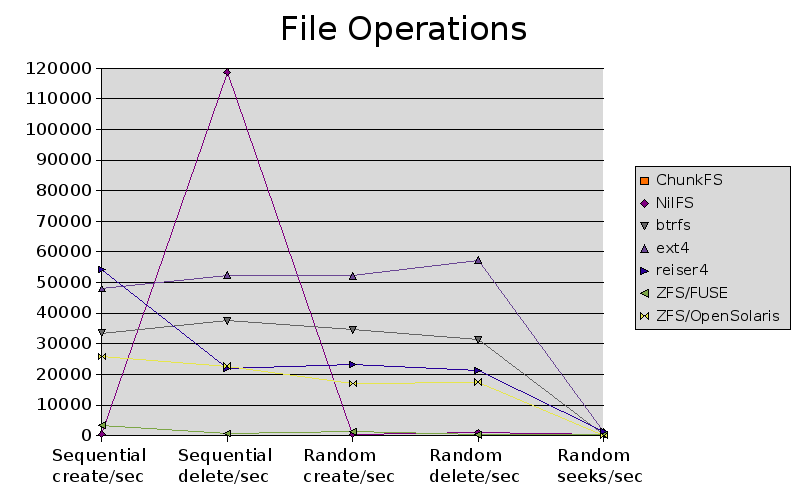
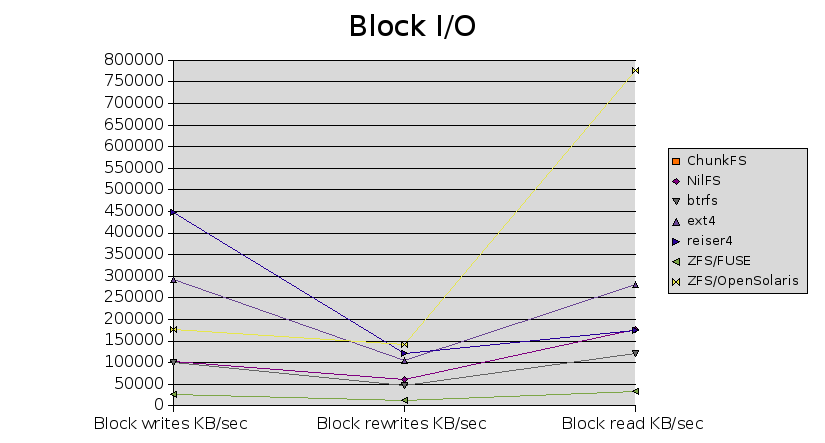
| Test | ext2 | ext3 | xfs | jfs | reiserfs | ChunkFS | NILFS | btrfs | ext4 | reiser4 | ZFS/FUSE | ZFS/OpenSolaris |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Sequential create/sec | 651 | 53412 | 2894 | 5562 | 29107 | N/A | 495 | 33454 | 48103 | 54286 | 3446 | 25833 |
| Sequential stats/sec | +++++ | +++++ | +++++ | +++++ | +++++ | N/A | +++++ | +++++ | +++++ | +++++ | 4155 | 56906 |
| Sequential delete/sec | 204531 | 60123 | 4602 | 2761 | 24549 | N/A | 118726 | 37457 | 52397 | 21880 | 727 | 22659 |
| Random create/sec | 639 | 52744 | 2643 | 1556 | 28179 | N/A | 495 | 34521 | 52234 | 23215 | 1195 | 17033 |
| Random stat/sec | +++++ | +++++ | +++++ | +++++ | +++++ | N/A | +++++ | +++++ | +++++ | +++++ | 3250 | 52337 |
| Random delete/sec | 1204 | 59555 | 2109 | 1432 | 16623 | N/A | 993 | 31331 | 57264 | 21318 | 205 | 17519 |
| Block writes KB/sec | 648084 | 275239 | 617869 | 327055 | 359405 | N/A | 102669 | 101102 | 291673 | 446526 | 27017 | 176336 |
| Block rewrites KB/sec | 123908 | 115008 | 128171 | 128943 | 116784 | N/A | 60190 | 46907 | 103971 | 122194 | 11529 | 142455 |
| Block read KB/sec | 294471 | 309794 | 246910 | 279747 | 215436 | N/A | 177609 | 121205 | 281596 | 173377 | 31963 | 777394 |
| Random seeks/sec | 1007 | 991.9 | 1404 | 1060 | 989.1 | N/A | 519.6 | 257.8 | 1245 | 1249 | 273.1 | 857.1 |
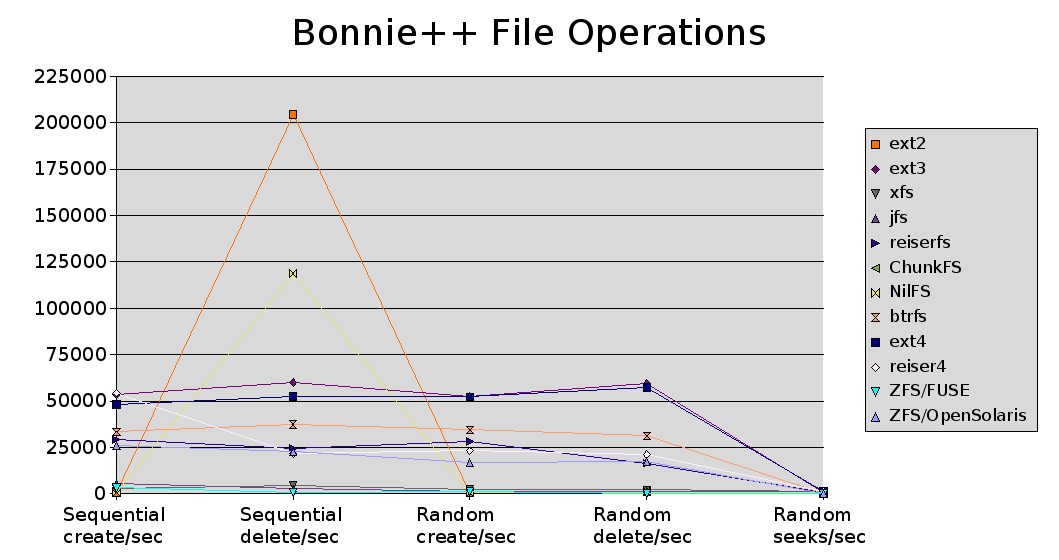
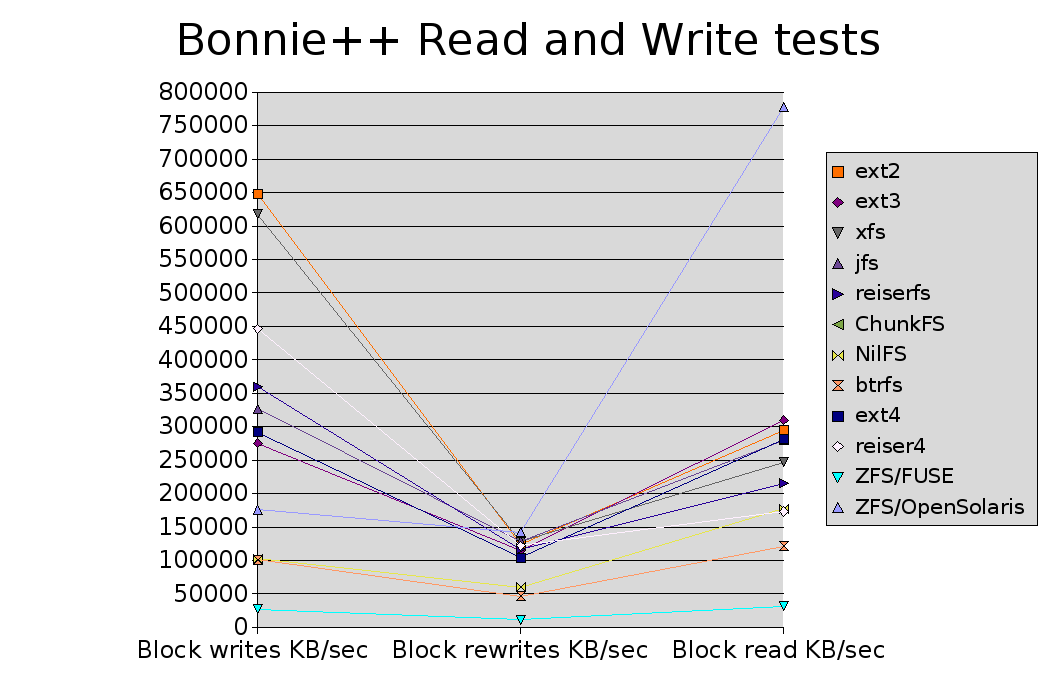
There is a great range of innovation in the various emerging filesystems tested here. It ranges from the rather conservative ext4 model of extending an existing filesystem with some new features through porting an existing stable filesystem to a new platform (ZFS/FUSE) to completely new code bases that integrate some of the current hot concepts in filesystem design (btrfs & nilfs).
The filesystems that have impressed me most are ZFS/FUSE for its comprehensive feature set, btrfs for creating a kernel level filesystem with checksum support and nilfs for its creative continuous checkpointing system and the ability to convert a checkpoint to and from a persistent snapshot at will.
Lets face it, emerging filesystems are probably not what you'd really be wanting to use for your business critical data, or even your working home directory, unless you're very brave and have good backups.
ChunkFS has a long way to go from what I have seen of it, the ideas behind it are nice but it's far to much on the painful side of bleeding edge at the moment.
Whilst btrfs didn't crash during testing you do need to keep in mind that the on-disk format isn't fixed yet, so you're highly likely to find that later versions won't read current filesystems, and the fact that it (apparently) blows up spectacularly if it runs out of disk space should keep you on your toes.
Reiser4 has been around since 2003, so I was rather surprised to have it crash messily on me the first time around - whilst it is possible that it could have been related to some transient hardware issue it does seem unlikely.
ZFS/FUSE currently has a shadow hanging over it regarding potential corruption of RAIDZ arrays, though there are not enough details about the problem to know quite what is going on here. The mirroring option, however, is apparently not affected by this.
The final two filesystems, nilfs and ext4, are also still under active development and so you should expect all sorts of interesting things to possibly happen to your data!
OK, so we all know that filesystems benchmarks are really good at showing which filesystems excel at filesystem benchmarks, but not necessarily which are good for real world use. My hope is that somewhere in the range of benchmarks chosen here are one or two metrics that may be of help to you when looking at what filesystems to experiment with.
My biggest surprise here was that two existing stable filesystems, ext2 and XFS, so roundly trounced all the other filesystems on block writes - even Reiser4, of which Namesys have made such great claims.
ZFS/FUSE performs badly all round, which is not surprising given the fact that no performance tuning has yet happened in the FUSE port. ChunkFS also doesn't do too well in the tests it does complete in.
The only other standout was that both ext2 and nilfs are exceptionally good at removing large numbers of files sequentially.
My gut feeling is that btrfs is going to get quite a bit of attention, the fact that it checksums the data on the platter will give people a nice sense of security whilst the ability to do snapshots is valuable. I do wonder, however, how people will cope with not being able to write into the top level filesystem. Still if that is /home and you just create sub-volumes in there per user it may not be too bad.
I also think that nilfs is one to watch as it has a really well thought out checkpointing/snapshot system and user interface. Ext4 will likely succeed ext3 in the kernel, though the fact that once you've mounted it as ext4 as written a file you can no longer mount it as ext3 will cause some pain.
Whatever happens, we are living in interesting times in filesystem development, the next few years are going to be really fun!